


发布日期:2026-03-02 10:42 点击次数:93


机器之心剪辑部
统统这个词具身智能领域皆在探索寰宇模子的实用化旅途。这个被委托厚望的「数字模拟器」,本应成为机器东谈主老师的中枢器用,却因物理保真度低等问题成为「空中楼阁」。
视频贯串:https://mp.weixin.qq.com/s/kv7J95lcyjccJJq9JWZ8SQ
前年年中,谷歌发布了 Genie-3 寰宇模子,让「可交互的寰宇模子」第一次以极具冲击力的神色走进寰球视线。这是一个不错及时生成、及时交互的「无穷寰宇」:通过为止动作,用户不错张开简直无穷的场景演化旅途。
这一智商也速即被投射到具身智能领域 —— 要是机器东谈主也能在这么的寰宇模子中进行亿万次的老师,是否意味着通用机器东谈主果然垂手而得?
但当盘问者信得过尝试将「可交互寰宇模子」用于机器东谈主学习时,很快发现了一些绕不开的本造谣题:
1)寰宇模子擅长「看起来对」,却难以作念到「物理上对」;
2)由于机器东谈主数据大部分皆是告捷的 demo,寰宇模子老是过于乐不雅;
收尾是:寰宇模子的不准确性 + 过度乐不雅的能源学假定,使得 VLA 战略简直无法在其中安逸学习。

寰宇模子「盲目乐不雅地」自动补全了残骸的体式;寰宇模子「特地地」将着实寰宇里倒塌的方块误以为堆叠情景。
清华陈建宇(星动纪元独创东谈主)团队和斯坦福 Chelsea Finn(PI 独创东谈主) 团队基于 Ctrl-World (两个团队的首个互助效用),再度联袂,斡旋提议了 VLAW 框架,初次结束了 VLA 战略与动作要求寰宇模子的协同迭代优化,让两者酿成一个「彼此促进的闭环」:
VLA 战略蚁集的着实交互数据,反过来用于提高寰宇模子的物理保真度;
寰宇模子生成的高质料假造数据,再用于连接强化 VLA 战略自己。

机器东谈主学手段
试错的「膏火」贵到离谱
寰宇模子成要津期待
每次在着实机器东谈主上的试错(真机 rollout),皆需要东谈主工重置环境;一朝模子战略出错,机械臂还可能作念出危境操作,必须有东谈主全程盯着。着实寰宇的后老师数据范围,就这么被死死卡住了脖子,成了具身智能发展的中枢瓶颈。
能让机器东谈主在「遐想空间」无穷试错的寰宇模子,成为贬责这一问题的要津期待 —— 在完满的寰宇模子里,机器东谈主能在这个「遐想空间」里无穷试错,生成海量合成数据练手,统统无须碰着实寰宇里上流的硬件建造,试错资本能降到简直为零。
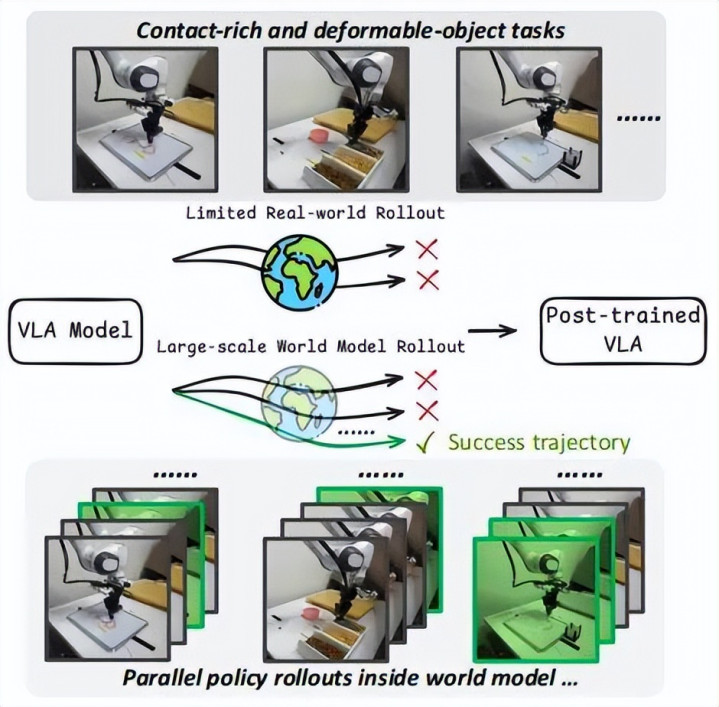
VLA 模子在着实寰宇的 rollout 耗时且难以膨大。在 VLAW 中,领先诳骗有限的着实寰宇在线 rollout 学习一个动作要求的寰宇模子,进而在遐想中生成大范围的合成数据
寰宇模子:
一座栏杆玉砌的「空中楼阁」
祈望很丰润,实践很骨感。现存寰宇模子存在二个致命颓势,让它成了一座「空中楼阁」,最终只会落得「垃圾进,垃圾出」的下场,让寰宇模子的实用化成为畅谈。
盲目乐不雅:老师数据大多是告捷的动作轨迹,没见罪责败案例,导致模子展望的收尾全是「祈望情况」,根底收复不了着实操作中的虚伪和只怕,无法贴合着实的操作场景;
交互、碰撞模拟痛苦:关于物体碰撞、摩擦这类斗争密集型操作,或是纸巾、书册这类可变形物体的交互,模子根底捕捉不到那些狭窄但要津的物理细节,以至会生成空泛的画面,丧失了物理建模的中枢价值;
VLAW 破局:
让 VLA 和寰宇模子双向奔赴
打磨出实用的寰宇模子
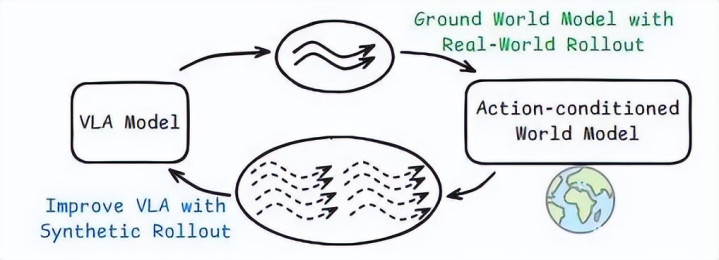
VLA 战略在线 rollout 数据有助于将预老师的寰宇模子适配到卑劣任务中。一朝寰宇模子完成适配,就能为 VLA 战略学习生成海量数据
VLAW 的中枢解法,让 VLA 战略的着实数据校准寰宇模子,以校准后的寰宇模子反哺 VLA 战略,在这个双向奔赴的过程中,寰宇模子的颓势被逐个贬责,物理保真度和数据生成智商连接提高。
四步走:
把「让寰宇模子有用」的想法落地成工程
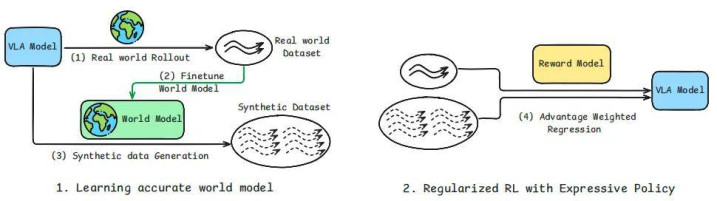
VLAW 的责任过程:(1) 领先在着实寰宇中实行战略以蚁集极少在线轨迹;(2) 诳骗这些战略 rollout 数据微调预老师的动作要求寰宇模子,使寰宇模子适配办法任务并提高其展望保真度;(3) 诳骗优化后的寰宇模子,通过战略与寰宇模子的闭环交互生成大范围合成轨迹;(4) 最终,诳骗视觉 - 谈话奖励模子自动评估奖励,链接着实寰宇和合成数据优化 VLA 战略
从表面念念路到实质落地,VLAW 遐想了四个精密咬合的时势,通过迭代优化结束「让寰宇模子有用」的中枢办法,同期让机器东谈主借助校准后的寰宇模子完成「在遐想中变强」的老师。
第一步:使用着实 rollout 数据微调寰宇模子,戒掉盲目乐不雅
盘问团队用包含告捷与失败的着实机器东谈主在线轨迹数据微调预老师寰宇模子;同期为了审视模子过拟合,还加入了原始的 DROID 数据集一齐老师,让它既能看懂失败,又不会过拟合,确保对着实场景的收复度。
第二步:使用 Qwen-VL 评判轨迹
团队基于 Qwen3-VL-4B-Instruct 微调了一个视觉 - 谈话奖励模子,用着实数据里的告捷 / 失败标签校准它的判断智商,能自动判别寰宇模子生成数据的厉害。
第三步:活着界模子中生成巨额数据
在校准后的寰宇模子里,让机器东谈主战略进行大范围的 rollout,每个任务皆生成 500 条合成轨迹。这一步即是机器东谈主在「遐想中」练手,但因为寰宇模子还是被着实数据校准,这些「遐想中的数据」的质料大大提高。
第四步:学告捷样本优化战略,反向为寰宇模子校准提供更优质数据
把着实寰宇里的告捷轨迹,和寰宇模子生成的优质合成告捷轨迹混在一齐,用简便的监督学习办法来更新机器东谈主的 VLA 战略。原因很实质:关于流匹配、扩散这类生成式战略,强化学习需要计算特定情景下的动作概率密度,但这类战略的动作是从噪声一步步推导出来的,概率计算难度极高。团队还从表面上评释,这种加权回想办法,其实是正则化强化学习的一种相通步地,兼顾了简便性和有用性。
而 VLA 战略的优化与性能提高,又能在着实寰宇中产生更优质的试错数据,为寰宇模子的下一轮校准与优化提供更好的基础,酿成寰宇模子与 VLA 战略彼此树立的闭环。
实测见真章:
模拟器从「祈望家」变「求实者」
盘问团队遐想了一个动作重放的评估门径:把着实机器东谈主的动作序列输入寰宇模子,让它生成对应的视频,再和着实寰宇的视频对比,从视频质料和物理交互收尾两个维度作念定量评估:
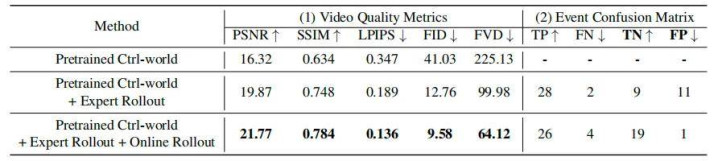
活着界模子中重放记载的动作序列。(1) 在 256 个重放片断(每个 5 秒)上评估视频质料蓄意,澳门十大信誉网络赌城统统蓄意均通过腕部视角相机计算,该视角最能捕捉操作过程中的物体交互;(2) 交互阶段是舛错的主要开始,因此在 50 个波及物理交互的片断上施展事件级玷污矩阵,为每个片断标注交互收尾(告捷 / 失败),并将模子展望与着实寰宇收尾对比
收尾一目了然:
1. 经过着实试错数据微调后的寰宇模子,在 PSNR、SSIM 等视频质料蓄意上,全面跳跃了原始预老师模子,以及仅用行家告捷数据微调的模子,生成的视频画面更贴合着实;
2. 更伏击的是,它的假阳性率大幅镌汰,再也不会把失败的操作「脑补」成告捷,精确贬责了「乐不雅病」,能着实收复操作中的成败收尾。

在调换的运行帧和统统调换的动作序列要求下,在不同寰宇模子中实行轨迹推演。预老师的 Ctrl-World 模子关于这些斗争密集型任务的精度不及;仅用行家轨迹微调的寰宇模子时常过于乐不雅;相悖,用战略在线 rollout 数据微调的寰宇模子能准确捕捉底层的物理能源学,与着实寰宇的收尾高度吻合。
3. 哪怕是 20 秒的永劫程假造试错,生成的视频也能保持较高的物理合感性。


从运行不雅测脱手,活着界模子中进行永劫程战略闭环 rollout 的示例。π0.5 战略实行 20 次迭代(20 秒),微调后的寰宇模子与着实寰宇高度一致。上:着实寰宇 下:寰宇模子
比如舀花生入碗、用纸巾擦白板绚烂这类需要精确物理交互的任务,预老师的寰宇模子统统持不住细节,仅用行派系据微调的模子则过于乐不雅,而经 VLAW 校准的寰宇模子,能精确捕捉底层的物理能源学,生成的收尾和着实寰宇高度吻合。
要津数字:
校准后的寰宇模子
相沿机器东谈主复杂任务性能大幅跃升

实验在 DROID 平台上开展,涵盖五类任务,如图所示。这些任务波及复杂的物理交互,包括鄙俚的斗争和可变形物体,难以在传统仿真中建模。
盘问团队在 DROID 机器东谈主平台上,针对堆叠积木、绽放书册、擦除白板绚烂、舀取颗粒、画圆五类复杂任务作念了实测 —— 这些任务皆波及鄙俚的物理斗争或可变形物体操作,是传统仿真模子很难建模的场景,也恰是考验寰宇模子实用价值的要津场景。实验用现时 SOTA 的 π0.5 动作基础战略,Ctrl-World 动作基础寰宇模子,每轮迭代在 5 类任务上共蚁集 250 条着实轨迹(每类任务 50 条)用于寰宇模子的校准,而经校准后的寰宇模子,最终交出了一份亮眼的收获单,相沿机器东谈主战略在五类任务中结束告捷率的大幅提高。从全体弘扬来看,各门径的告捷率提高对比收尾了了深远 VLAW 的上风。
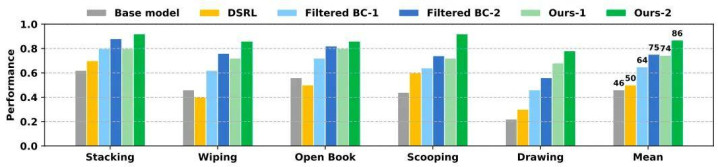
与基线门径的告捷率提高对比。进行了两轮迭代老师,「Ours-1」示意 VLAW 门径经过第一轮在线 rollout 后的收尾。总体而言,在多任务竖立下 VLAW 连接优于 Filtered BC 和 DSRL 基线
团队还可视化了着实 rollout 与寰宇模子生成的合成 rollout 对比,了了展现了经校准后的寰宇模子,能为着实寰宇的失败案例找到告捷的贬责旅途,其生成的合成数据具备极高的老师价值。在着实寰宇 rollout 中,机器东谈主未能收拢勺子、未能画出完整的圆,而借助 VLAW 打磨后的寰宇模子,能从调换运行帧起程,为这些失败案例生成告捷的轨迹,让机器东谈主能从「失败教授」里学会正确的作念法,这恰是寰宇模子实用化的中枢体现。

GT 代表着实寰宇的 rollout,0~14 代表寰宇模子生成的多种遐想轨迹,统统轨迹均从调换的 GT 运行帧起程并使用 π0.5 战略。在着实寰宇 rollout 中,机器东谈主未能收拢勺子(左,GT)且未能画出完整的圆(右,GT)。借助寰宇模子,咱们能为这些失败案例找到告捷的轨迹,这对战略学习具有伏击意旨
不仅如斯,消融实验还进一步评释了 VLAW 打磨寰宇模子的中枢逻辑:要是减少寰宇模子生成的合成数据的数目,或是平直移除校准寰宇模子的着实数据,机器东谈主战略的性能皆会清醒着落。这意味着,寰宇模子的校准质料和合成数据产出量,平直决定了机器东谈主战略的提高效果,也再次印证了「让寰宇模子变得有用」是 VLAW 框架的中枢要津。
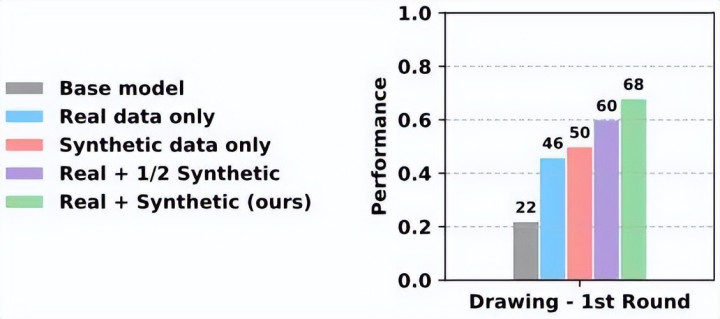
消融实验盘问了 (1) 用于策稍稍调的合成数据量(从 500 条减少到 250 条)和 (2) 微调时是否包含着实寰宇 rollout 数据(50 条)。实验发现,减少合成轨迹数目或移除着实寰宇数据集皆会导致性能着落
将来:
机器东谈主先在遐想里「满级」
再落地着实生计
现在 VLAW 的实验考据斡旋在五类任务上,盘问团队示意,将来的盘问将围绕寰宇模子的范围化和泛化性张开,连接提高寰宇模子的智商,让其能适配更多场景、更强的模子,信得过成为通用机器东谈主战略学习的中枢器用:
{jz:field.toptypename/}一是把着实试错数据膨大到更各类的机器东谈主操控任务中,提高寰宇模子的通用泛化智商;
二是链接更先进的视频生成模子,让寰宇模子的视觉展望和物理建模智商更进一竿。
在盘问团队看来,跟着视频生成模子的连接发展,以及大范围机器东谈主交互数据的不断积存,让寰宇模子变得更通用、更精确、更实用,并基于打磨后的寰宇模子构建老师范式,将成为通用机器东谈主战略学习的中枢所在。
将来的机器东谈主,大要会先在由优质寰宇模子打造的假造寰宇里完成「满级老师」,把各类手段练到行云活水,再无缝落地到着实寰宇,冷静完成各类复杂的操控任务。而 VLAW,恰是寰宇模子实用化的伏击探索,为这一将来所在奠定了坚实的基础。
上一篇:澳门赌城app 机构: 2025年下半年世界智能眼镜出货量同比增长139%, 小米暴增200%跃居第二
下一篇:没有了
 备案号:
备案号: